

Google Shows Off Flexible New Generative AI Video Model VideoPoet
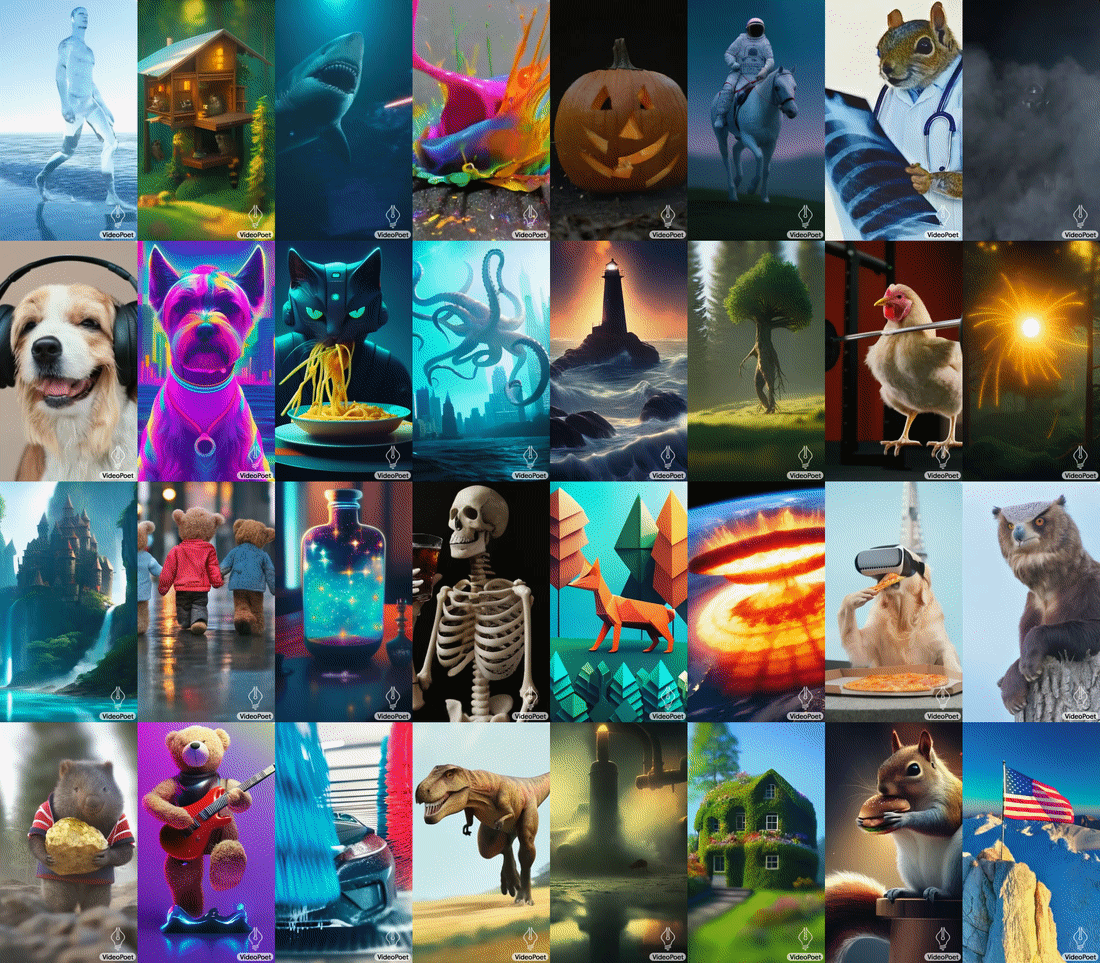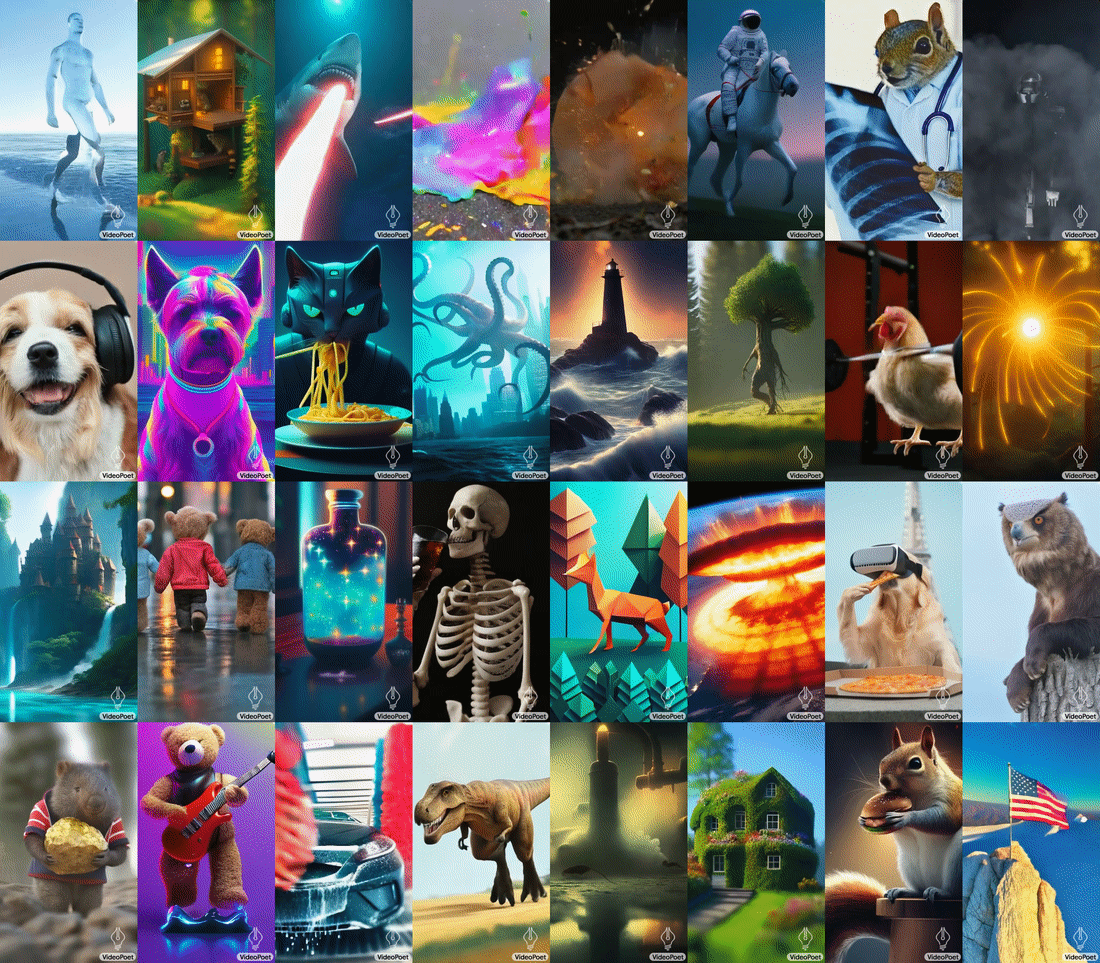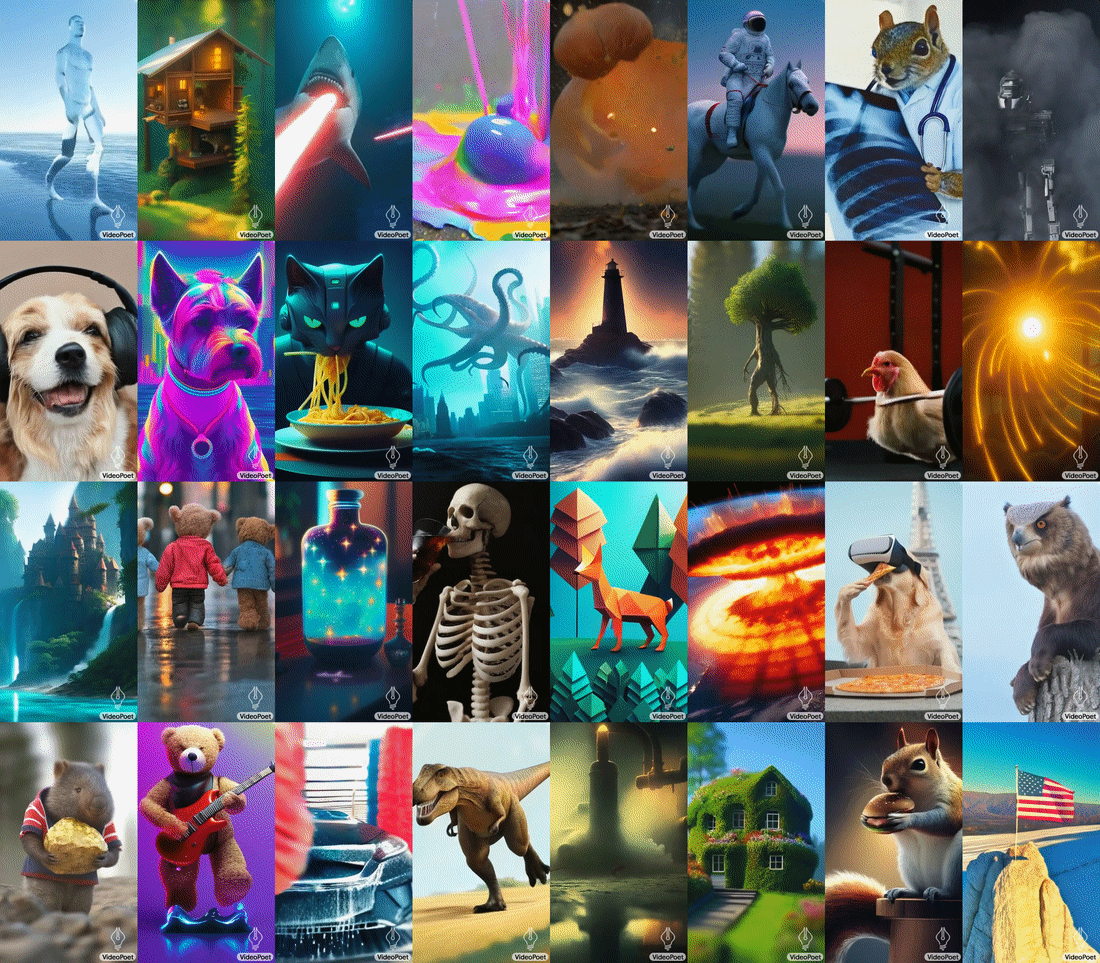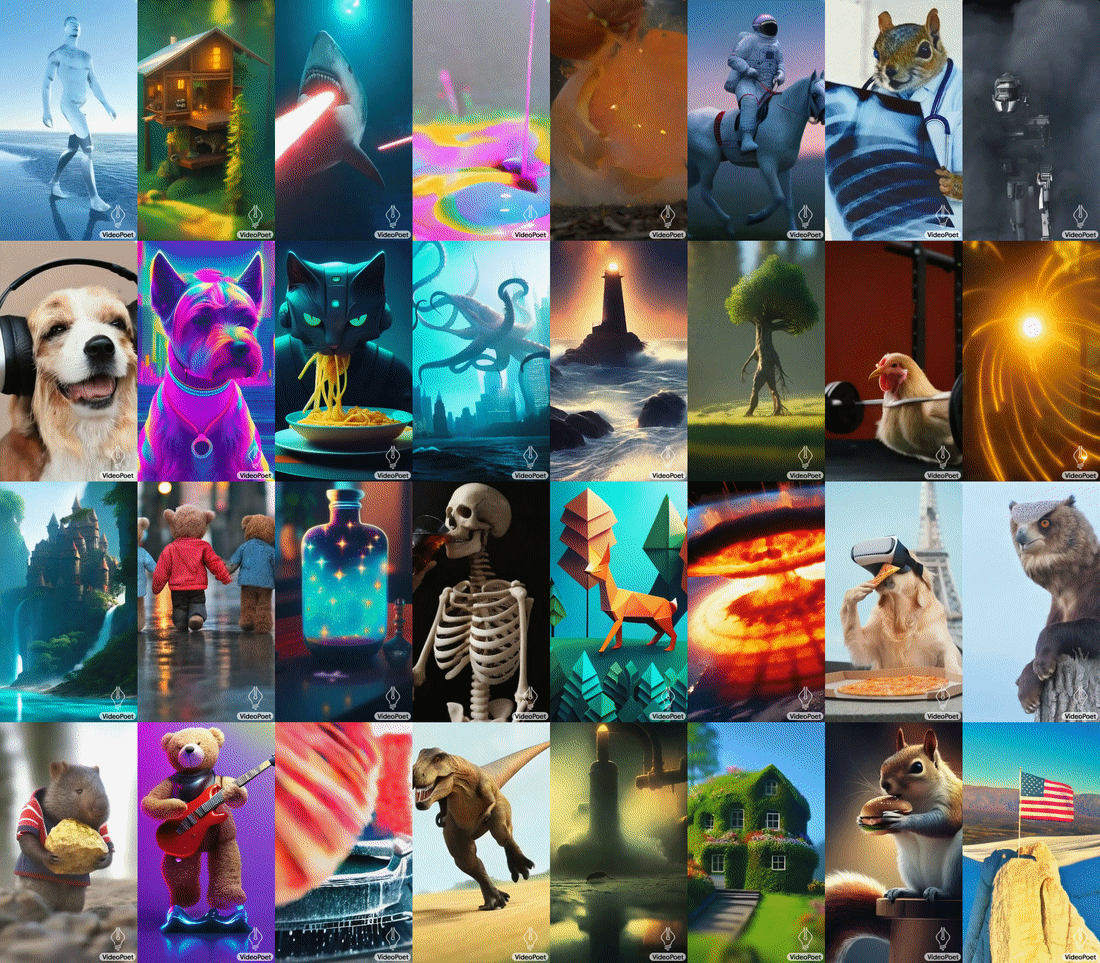 Google Research has unveiled a new large language model (LLM) specifically designed for a wide range of video generation tasks. The new VideoPoet LLM offers text-to-video, image-to-video, and video-to-audio conversion, integrating multiple synthetic video production capabilities within a single LLM.
Google Research has unveiled a new large language model (LLM) specifically designed for a wide range of video generation tasks. The new VideoPoet LLM offers text-to-video, image-to-video, and video-to-audio conversion, integrating multiple synthetic video production capabilities within a single LLM.
VidePoet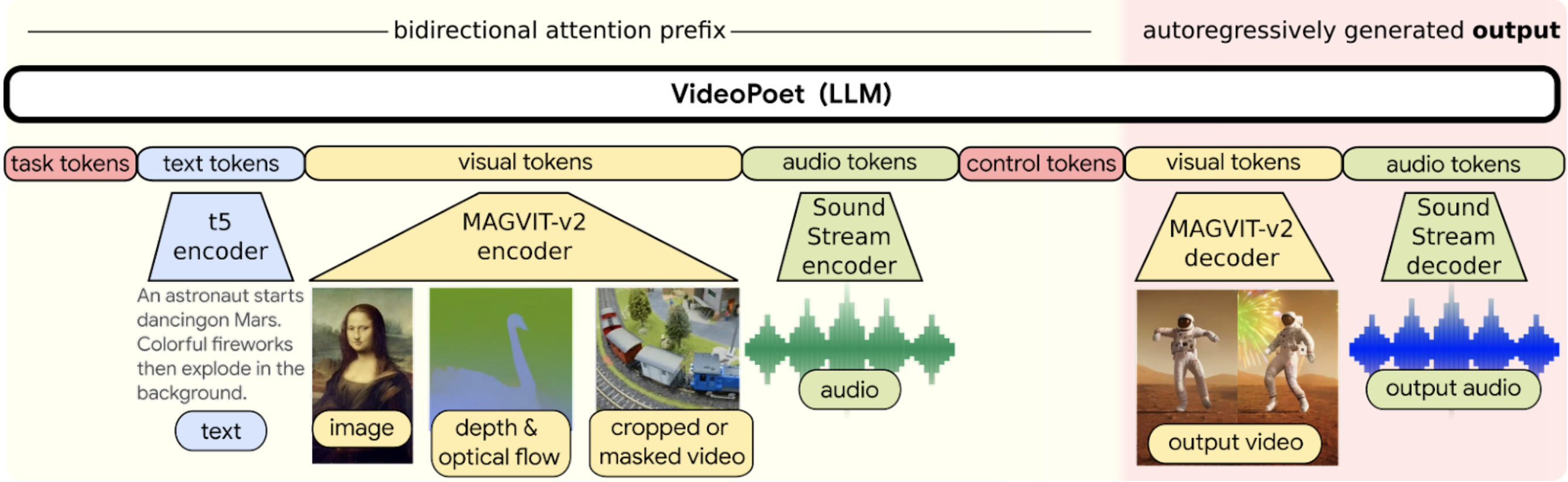
VideoPoet was created to show how one LLM can handle several high-quality video generation elements that can emerge from a single model rather than requiring one for each kind of task. The model trains on diverse video, image, audio, and text data using automated tokenization. This allows flexible conditioning and control over what the model produces, as seen in the chart above.
Google’s tests of VideoPoet demonstrated a higher accuracy score in matching text prompts and motion compared to other models despite relying on a single LLM rather than multiple specialized models. Longer videos can also be created by iteratively predicting each new second. The AI demonstrated coherent object appearances over time, even through repeated extensions. Google also showcased fine-grained editing of generated clips by tweaking text prompts. This includes manipulating object motions and adding camera directions like “pan left” or “crane shot.”
“One key advantage of using LLMs for training is that one can reuse many of the scalable efficiency improvements that have been introduced in existing LLM training infrastructure. However, LLMs operate on discrete tokens, which can make video generation challenging,” Google Research software engineers Dan Kondratyuk and David Ross explained in their paper. “Fortunately, there exist video and audio tokenizers, which serve to encode video and audio clips as sequences of discrete tokens (i.e., integer indices), and which can also be converted back into the original representation.”
To show off everything VideoPoet can do, the researchers put together multiple clips produced by VideoPoet. They asked Google Bard to write a story about a raccoon going on a trip, with scene breakdowns of a script and suggested prompts. They then combined the video for each prompt, and you can see the result below.
“Through VideoPoet, we have demonstrated LLMs’ highly-competitive video generation quality across a wide variety of tasks, especially in producing interesting and high quality motions within videos,” Kondratyuk and Ross concluded. “Our results suggest the promising potential of LLMs in the field of video generation. For future directions, our framework should be able to support “any-to-any” generation, e.g., extending to text-to-audio, audio-to-video, and video captioning should be possible, among many others.”
Follow @voicebotaiFollow @erichschwartz






