
Microsoft Debuts 3-Second Voice Cloning Tool VALL-E
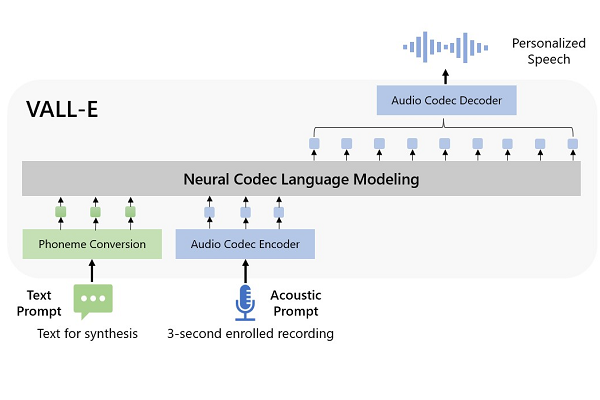
Microsoft has introduced a text-to-speech AI model capable of cloning a person’s voice with just three seconds of audio as an example in a research paper. The new VALL-E model can extrapolate enough from those three seconds to synthesize the voice saying anything a user wants, a far more efficient model than the versions that require many minutes or hours of audio samples.
VALL-E Voices
VALL-E is what the researchers refer to as a “neural codec language model” and uses Meta’s EnCodec technology. A human voice is analyzed as individual tokens through EnCodec, and the AI can then estimate how the voice would sound when making the noise of other words. As a result, VALL-E produces audio codec codes from text and acoustic prompts instead of the traditional waveform manipulation method. The script a user feeds into the model is processed with the acoustic tokens of the original recording and sound prompts to generate the right waveform according to the neural codec decoder.
The utility of VALL-E is in its efficiency. Producing voice clones out of a tiny fragment of their voice could be useful for quickly generating a range of voice clones, especially if it is even more audio for the model to work with. To reach this point, VALL-E trained on the Meta-organized LibriLight audio collection of more than 60,000 hours of English spoken by more than 7,000 individuals. The model is good enough to replicate not only the sound of a speaker and their emotion, but even the environment where they speak, so it could clone the sound of a voice in the same room or on a telephone call, for instance.
“VALL-E emerges in-context learning capabilities and can be used to synthesize high-quality personalized speech with only a 3-second enrolled recording of an unseen speaker as an acoustic prompt,” the researchers wrote in their paper. “Experiment results show that VALL-E significantly outperforms the state-of-the-art zero-shot TTS system in terms of speech naturalness and speaker similarity. In addition, we find VALL-E could preserve the speaker’s emotion and acoustic environment of the acoustic prompt in synthesis.”
The skyrocketing demand for all kinds of synthetic media means VALL-e is likely to draw plenty of interest in the race to for better, faster, and more flexible voice models. Companies are eager to boast of improvements and new features, as exemplified recently by Nvidia’s upgraded Riva synthetic speech engine, D-ID’s new platform, and Neosapience rolling out an AI-powered tool allowing users to write out the emotion they want virtual actors to use when speaking.
Follow @voicebotaiFollow @erichschwartz
Voicemod Debuts AI Text-to-Song Generator After Acquiring Synthetic Singing AI Startup Voctro
Synthetic Steve Jobs Interviewed by Deepfake Joe Rogan for AI-Powered Podcast Scripted by GPT-3






