
SoundHound Unveils Multimodal ‘Dynamic Interaction’ Feature for Business Smart Displays
SoundHound has introduced a new conversational AI feature called Dynamic Interaction as a way for businesses to apply voice AI technology to their services. Dynamic Interaction combines a real-time understanding of partial phrases and sentence fragments with a screen and audio AI integration for customer services.
Dynamic AI
The Dynamic Interaction feature combines natural language understanding for fragmentary phrases with visual augmentation of the voice interaction. SoundHound describes how a restaurant customer might place an order using a voice-enabled interface and speak the same way they would to a human. That means the AI-based order-taking application would be able to maintain context, handle ambiguity more deftly, and navigate indefinite pronouns and articles, partial sentences, interruptions, or asides.
In addition, the customer won’t have to wait for the AI to finish speaking before adjusting the order. This feature is sometimes called barge-in, as the user can barge into the conversation while the AI is speaking or thinking to add different or clarifying information without having to wait for the AI to finish its turn. The AI will also ignore anything said that’s not related to the menu.
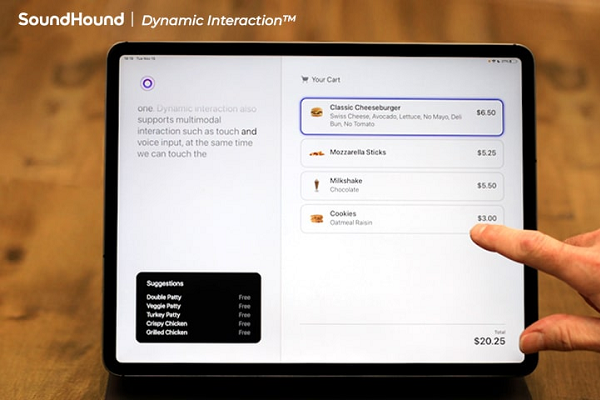
A customer order appears on a screen as it’s placed in the SoundHound example, assuring the customer that their order and any changes are confirmed, even allowing them to change the order via the touchscreen. The AI balances its audio and visual responses as appropriate and makes proactive suggestions, showing possible desserts on the screen when the customer mentions the word. You can see an example in the video up top.
Full Duplex Communication
SoundHound’s new solution falls into the technical category of full duplex communication. This means that information can flow in both directions simultaneously. This contrasts with half duplex solutions like nearly every other voice assistant solution available today. With half duplex, information can only flow one way at a time. This requires serial turn taking and is the interaction method common to Alexa, Bixby, Google Assistant, Siri, and so on. There is no barge-in. You must wait for the AI top finish its steps before adding to or revising your request.
Microsoft’s XioaIce chatbot team made a big deal of this when launching in 2018. Granted, they referred to it as a higher level of intelligence which is incorrect. A full duplex solution is not more intelligent, it just seems more intelligent because it is more humanlike in its flexibility.
Speechly was one of the first companies to demonstrate this capability for conversational interactions. They provided several demos, from shopping to airline booking. There are two elements that make full duplex UIs very different from other voice and touch interfaces. First, the speech recognition is immediately trying to determine the user’s intent and begins populating the screen with an answer. As the user continues speaking, the intent recognition is refined, and if the first guess was incorrect, new services or information are loaded to fulfill the actual intent.
Second, because the information and sometimes the text populates a screen in real-time, if the user identifies an error on the screen, they can revise their request or correct the AI’s interpretation before completing their request. This is not technically a barge-in feature because it remains the user’s turn in the conversation. Instead, this reflects the ability to revise or refine the request and confirm that the AI is on the right track. In this design, multimodal interfaces combined with voice offer an enhanced user experience.
It is not surprising that SoundHound’s expansion into restaurant use cases was followed by a full duplex feature. Simultaneous bi-directions communication is particularly beneficial when placing complex orders where the opportunity to be misunderstood is significant. Substitutions and other preferences lead to a wide variety of order combinations. With that said, we have not seen full duplex features in production. SoundHound’s announcement suggests that will soon change.
“As the Dynamic Interaction demo shows, this technology is incredibly user-friendly and precise. Consumers won’t have to modify how they speak to the voice assistant to get a useful response – they can just speak as naturally as they would to a human. As an added bonus, they’ll also have the means to instantly know and edit registered requests,” SoundHound CEO Keyvan Mohajer said.
SoundHound Advances
The new feature comes just as SoundHound has begun reducing its workforce by 10%, as announced in its quarterly stock report. The layoffs came despite the company beating analyst expectations Mohajer has pointed to continual growth in revenue and new products as indicators of the company’s upward trajectory.
In the last quarter, SoundHound has deployed new features for on-device and cloud voice AI, and introduced a real-time transcription and annotation service. The company has also begun integrating its voice AI into the Harman Ignite Store for cars, and deployed its first Mandarin language outlet as a feature for Dongfeng Peugeot Citroën Automobiles (DPCA) vehicles in China, contracted with Stellantis in Europe.
“In our 17-year history of developing cutting-edge voice AI, this is perhaps the most important technical leap forward. We believe, just like how Apple’s multi-touch technology leapfrogged touch interfaces in 2007, this is a significant disruption in human-computer interfaces,” said Mohajer.
Follow @voicebotaiFollow @erichschwartz
SoundHound’s Voice AI is Coming to the Harman Ignite Automotive App Store
SoundHound Beats Analyst Expectations But Lays Off 10% of Workforce
SoundHound Debuts Real-Time AI Transcription and Annotation Service






