

Nvidia Shows Off Virtual CEO Creation in New Documentary
 Nvidia created a virtual version of CEO Jensen Huang and quietly snuck in 14 seconds of the virtual human into his speech at the company’s conference this year with almost no one noticing. The virtual human moved and spoke like Huang in a digital reality that highlighted Nvidia’s tech, as explained in a new half-hour documentary about the making of those 14 seconds.
Nvidia created a virtual version of CEO Jensen Huang and quietly snuck in 14 seconds of the virtual human into his speech at the company’s conference this year with almost no one noticing. The virtual human moved and spoke like Huang in a digital reality that highlighted Nvidia’s tech, as explained in a new half-hour documentary about the making of those 14 seconds.
Virtual Keynote
Huang gave his 108-minute keynote address from his kitchen counter at first. Then, he appears to enter a virtual space like a shift in the Matrix films, ending at a DGX Station A100 in a digital world and, subtly, a digital self. Paying close attention shows Huang behaving slightly stiffly and speaking perhaps a touch more stiltedly. Still, both can be attributed to the performance he has to give if you were unaware of the circumstances. The decision to make the invisible switch at GTC was a part of that event’s overall demonstration of Nvidia’s work.
“GTC is, first and foremost, our opportunity to highlight the amazing work that our engineers and other teams here at Nvidia have done all year long,” Nvidia vice president of Omniverse engineering and simulation Rev Lebaredian said in a statement. “There are already great tools out there that people use every day in every industry that we want people to continue using. We want people to take these exciting tools and augment them with our technologies.”
Those tools included Nvidia’s Universal Scene Description (USD), Material Design Language (MDL) and NVIDIA RTX real-time ray-tracing technologies. Nvidia scanned his face and body for the digital Huang, filming with many cameras at multiple angles to create a 3D model. An actor in a motion-capture suit read out old letters from Huang and imitated his movements, which helped Nvidia design 21 3D models for an AI to analyzed and build a ‘virtual skeleton.’ AI also learned Huang’s expressions and mannerisms to mimic them. Using the Audio2Face and Audio2Gestures programs, the AI learned to lipsync and move the virtual face and body to match the words Huang read. The avatar was then placed in the virtual space instead of a more common green screen approach where a real person is in a fake environment. It took a wide range of tools and techniques to build the final version of those few moments. Nvidia showed off all the details in their new documentary titled, “Connecting in the Metaverse: The Making of the GTC Keynote.”
Omniversal
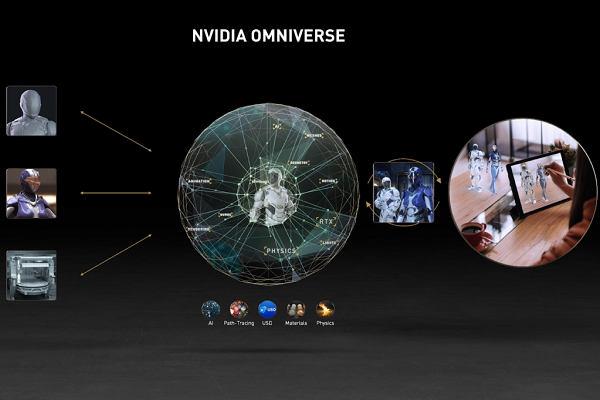 Audio2Face was first demonstrated at GTC last year as part of the Nvidia Jarvis AI. Voice data is used to animate three-dimensional skin and muscles on a virtual face. It’s one of the hundreds of pre-trained models for Jarvis using Nvidia’s GPU technology, which is also the engine for the Omniverse creations Huang talked about this year, as seen in the image above. The enterprise value of virtual humans has risen rapidly over the last few years, and new and improved virtual human tools and creations are appearing all the time. Unreal’s launch of MetaHuman Creator in February seemed to spark new acceleration. AI voice and video startups like Hour One, Supertone, Resemble AI, Veritone, and DeepBrain are all nabbing funding and clients. Virtual humans are appearing in a wide array of venues, whether Nestle Toll House’s virtual human “cookie coach” Ruth, YouTube star Taryn Southern’s virtual clone, or CoCo Hub’s artificial popstars. Nvidia’s Omniverse combines many of its technologies for a comprehensive angle on all of the relevant elements, helping in its goals of leading virtual human and virtual universe development.
Audio2Face was first demonstrated at GTC last year as part of the Nvidia Jarvis AI. Voice data is used to animate three-dimensional skin and muscles on a virtual face. It’s one of the hundreds of pre-trained models for Jarvis using Nvidia’s GPU technology, which is also the engine for the Omniverse creations Huang talked about this year, as seen in the image above. The enterprise value of virtual humans has risen rapidly over the last few years, and new and improved virtual human tools and creations are appearing all the time. Unreal’s launch of MetaHuman Creator in February seemed to spark new acceleration. AI voice and video startups like Hour One, Supertone, Resemble AI, Veritone, and DeepBrain are all nabbing funding and clients. Virtual humans are appearing in a wide array of venues, whether Nestle Toll House’s virtual human “cookie coach” Ruth, YouTube star Taryn Southern’s virtual clone, or CoCo Hub’s artificial popstars. Nvidia’s Omniverse combines many of its technologies for a comprehensive angle on all of the relevant elements, helping in its goals of leading virtual human and virtual universe development.
“We built Omniverse first and foremost for ourselves here at Nvidia. We started Omniverse with the idea of connecting existing tools that do 3D together for what we are now calling the metaverse,” Lebaredian said. “If we do this right, we’ll be working in Omniverse 20 years from now.”
Follow @voicebotai Follow @erichschwartz
Nvidia’s New Jarvis AI Can Turn Voices into Interactive Faces
Nvidia Invests $1.5M in Mozilla Common Voice Open-Source Project






