
Nvidia ‘Superchip’ Blasts Past AI Benchmarks

Nvidia’s Grace Hopper CPU+GPU Superchip outperformed on the MLPerf industry benchmark tests, according to the chip-maker. The tests highlight the performance and versatility of Nvidia’s chips across the board, including the new large language model (LLM) GPT-J inference benchmark and an updated recommendation model. The Grace Hopper Superchip provided 17% more inference performance than Nvidia’s H100 GPUs, while Nvidia’s L4 GPUs sextuple Intel’s Xeon CPU performance.
Grace Hopper Superchips
The MLPerf benchmarks measure AI acceleration on representative tasks across data center servers, edge devices, and under constrained conditions. Nvidia’s Grace Hopper Superchip combines a Hopper GPU and Grace CPU, optimizing compute allocation between the two. In tests, Grace Hopper systems delivered top throughput across all MLPerf data center inference tests, while Nvidia’s HGX platform, packing eight H100 GPUs, also posted leading scores. The benchmark rounds provide a sense of real-world AI acceleration and point toward a strategy for adoption.
“Grace Hopper Superchips and H100 GPUs led across all MLPerf’s data center tests, including inference for computer vision, speech recognition and medical imaging, in addition to the more demanding use cases of recommendation systems and the large language models (LLMs) used in generative AI,” Nvidia director of product marketing Dave Salvator explained in a blog post. “Overall, the results continue NVIDIA’s record of demonstrating performance leadership in AI training and inference in every round since the launch of the MLPerf benchmarks in 2018.”
TensorRT-LLM
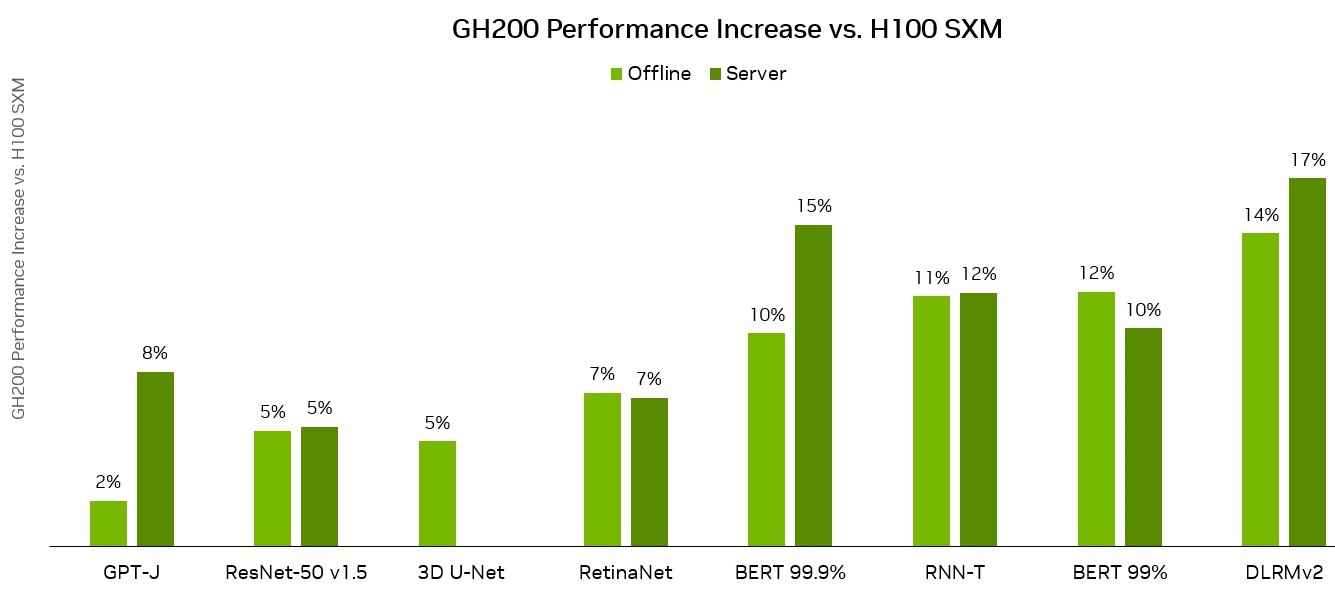
You can see the difference the Grace Hopper Superchip makes in the chart above. Nvidia suggests the MLPerf tests serve to make the new TensorRT-LLM software for upgrading LLM efficiency and inference processing ability more enticing. TensorRT-LLM leverages Nvidia’s GPUs and compilers to improve LLM speed and usability by a significant margin. The TensorFlow-based platform minimizes coding requirements and offloads performance optimizations to the software. The company’s TensorRT deep learning compiler and other techniques allow the LLMs to run across multiple GPUs without any code changes. Both upgrades extend Nvidia’s generative AI work from earlier this year. Since then, it has rapidly scaled up its operations, including working with Hugging Face to develop Training Cluster as a Service, a tool for streamlining enterprise LLM creation.
Follow @voicebotaiFollow @erichschwartz
Nvidia’s New TensorRT-LLM Software Pushes Limits of AI Chip Performance
Nvidia and Hugging Face Showcase New Generative AI Training Service
Nvidia Launches Enterprise Generative AI Cloud Services for Synthetic Media Engines






