
Allen Institute for AI Releases Largest Open Text Dataset Ever to Boost AI Research Transparency
 The Allen Institute for Artificial Intelligence (AI2) has released the largest open-source text dataset ever as a way of promoting transparency in AI research and development. The new Dolma dataset has 3 billion tokens and is slated to form the foundation for AI2’s planned open natural language model known as OLMo.
The Allen Institute for Artificial Intelligence (AI2) has released the largest open-source text dataset ever as a way of promoting transparency in AI research and development. The new Dolma dataset has 3 billion tokens and is slated to form the foundation for AI2’s planned open natural language model known as OLMo.
Dolma Data
AI2 has fully documented Dolma’s sources and preparation, including its filtering decisions. The corpus incorporates web pages, academic publications, books, encyclopedias, and code. All personal information was removed during preprocessing to protect privacy. The goal is maximal transparency into how the data is obtained and processed. Users must agree to disclose any models derived from Dolma and refrain from problematic use cases like surveillance. Individuals can also request the removal of personal information.
AI2 claims that by making both the data and model open, it can counter the opacity of datasets used by major companies like OpenAI and Meta because it will provide details beyond basic statistics. The openness will supposedly streamline external research and enhance accountability in terms of data sources and training methods. AI2 highlighted the lack of transparency from closed datasets in the chart of models below. Dolma includes all of the information in the columns, while most of these only include a few, if any, of the information researchers would be interested in knowing.
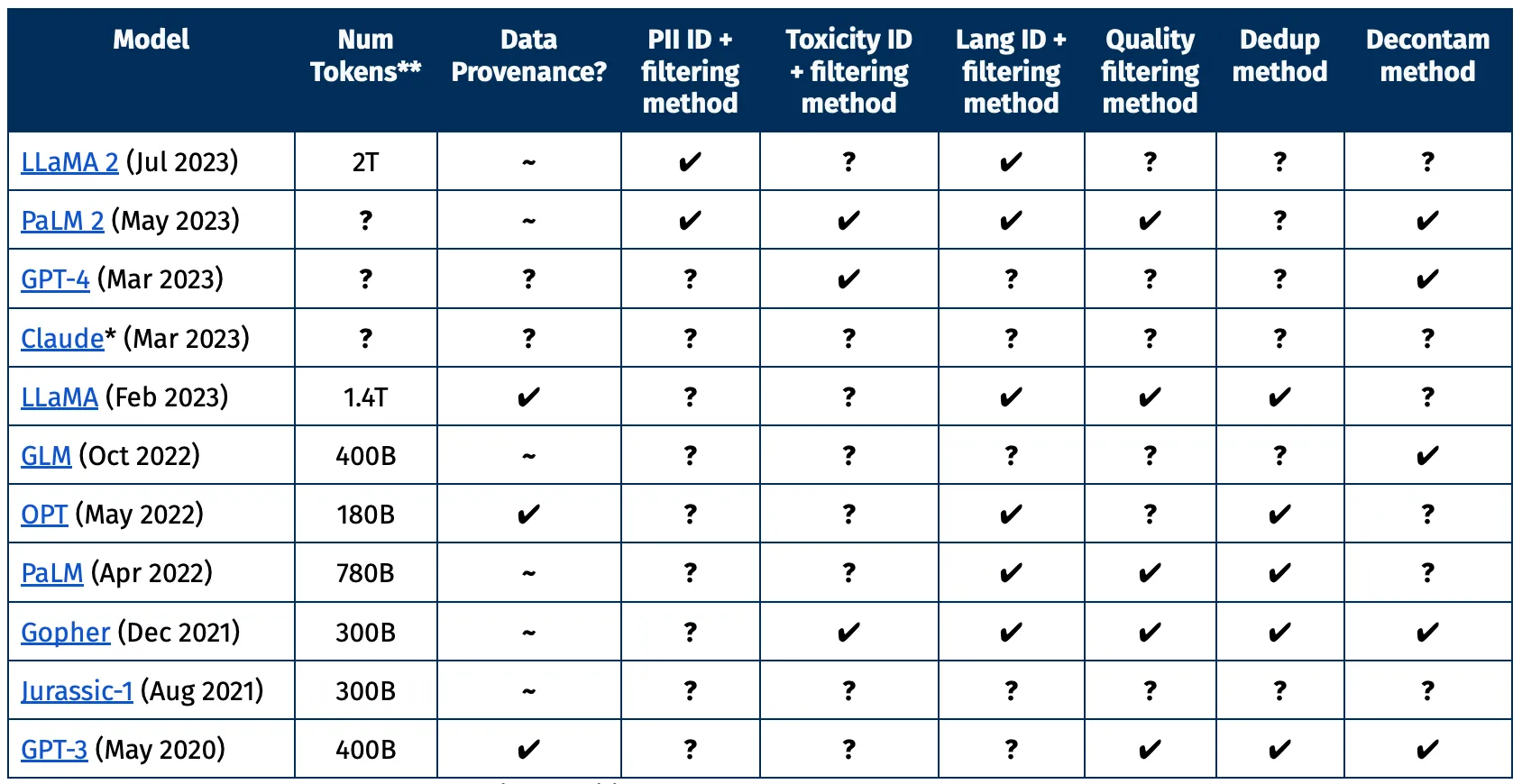
“Since March, we at the Allen Institute for AI have been creating OLMo, an open language model to promote the study of large-scale NLP systems. One of our major goals is to build OLMo in a transparent and open manner by releasing artifacts and documenting processes we followed throughout this project,” AI2 senior applied research scientist Luca Soldaini explained in a blog post. “Overall, we believe that our approach to Dolma is the most appropriate for our first foray in large-scale language modeling; that doesn’t mean it’s the best or only way. In fact, we are excited for future research into curating language modeling corpora, and we hope the Dolma dataset and tools to be valuable starting points for future research.”
At 3 billion tokens, Dolma certainly offers a hefty alternative for large language models. AI2 sees the size as a way to empower researchers to build ethical alternatives and inspect Dolma’s contents. Whether the transparency is enough on its own to allay other concerns during development remains to be seen as generative AI raises more concerns than can be addressed simply by seeing the ingredients for the LLM recipe. Still, Dolma does represent a potentially valuable new resource for those developing LLMs and generative AI tools. The open natural language model AI2 plans to release based on Dolma could lead to broader adoption of its methods too.
Follow @voicebotai Follow @erichschwartz
Ex-Google Researchers Launch Generative AI ‘Swarm’ Startup Sakana AI
Nvidia and Hugging Face Showcase New Generative AI Training Service
Salesforce Debuts ‘Bring-Your-Own-Model’ Generative AI Platform Einstein Studio






