
Speechly Releases Templates for Building Online Voice Interfaces
 Speech recognition tech startup Speechly introduced new templates for voice user interfaces (voice UIs) aimed at reducing any confusion or difficulties implementing vocal interactions on a website. The company released its new UI Component Library to Figma and Sketch for those interested in testing out the multi-modal designs.
Speech recognition tech startup Speechly introduced new templates for voice user interfaces (voice UIs) aimed at reducing any confusion or difficulties implementing vocal interactions on a website. The company released its new UI Component Library to Figma and Sketch for those interested in testing out the multi-modal designs.
Interface Update
Voice UIs are the tools used to understand what a user says and respond appropriately. But, Speechly has received plenty of feedback on the problems faced when voice is the only interaction. Users can get frustrated and annoyed when they try to speak with an AI but aren’t sure if it is operating correctly. Speechly’s new components address the issue by incorporating non-vocal elements for a multi-modal experience that avoids the common problems.
“At Speechly, we believe that many of the problems that exist with Voice UIs today can be mitigated or completely eliminated by adopting a Multi-Modal design philosophy,” Speechly CEO Otto Söderlund explained in announcing the voice UIs. “This means leveraging all the available modalities (voice, visual, touch) of the user’s context to make the user interaction as easy and smooth as possible. One of the most fascinating platforms for Multi-Modal Voice UIs is the web, but if you look for design patterns for adding voice features to web applications, you will quickly realize a lack of quality resources.”
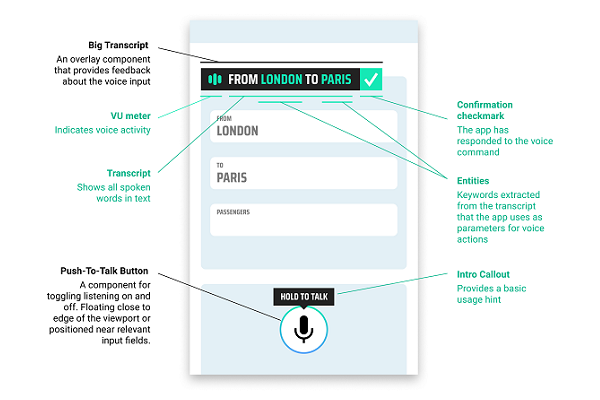
The UI library is Speechly’s way of creating those resources. The templates include four related facets to let users know when the voice AI is operating and if it is performing as it should. As can be seen in the image at the top, Speechly is offering a push-to-talk button option to control when the AI is listening, a real-time transcription that can either overlay the screen or slide down as a drawer depending on what the developer prefers, and an error panel that explains how to recover from voice issues the user might have. The components also come with a Design Philosophy Guide for using them based on Speechly’s theories on multi-modal voice interfaces. For now, the components are only usable online, though there may be a mobile version in the future.
Online Talk
The voice UIs are built to enhance Speechly’s existing speech recognition API, which already differs from the more standard conversational voice assistants available. Rather than respond to everything a user says, it is able to begin implementing requests before they finish speaking to reduce the response time, updating its work as the user expands and clarifies its requests. Not responding ups speed and efficiency, but, slightly ironically, is a reason users may not be sure it is working, hence the need for multi-modal elements like visual confirmation.
As demand for enterprise voice interactions online grows, this will be crucial for Speechly to compete with rivals looking to fulfill the same role. Startups like speak2web and its e-commerce focused voice plug-in for websites and apps have their own approach and broadly related tech. And Amazon and Google have begun to push their own voice AI tech to businesses. The market is still expanding quickly under many verticals, but when the tech giants make their moves, Speechly and its smaller rivals will need the advantages these kinds of features bring to the table.
Follow @voicebotai Follow @erichschwartz
Finnish Voice Recognition Startup Speechly Closes €2M Funding Round
Hannes Heikinheimo Co-founder and CTO at Speechly – Voicebot Podcast Ep 228
Voice Assistant Transactions Will Reach $19.4B by 2023: Report






