
Neural Text-To-Speech Development Allows Alexa to Sound More Realistic
We will likely be seeing Amazon roll out new speaking styles for Alexa soon. Last week, the Alexa Speech Team unveiled advances in neural-network-based speech synthesis that will ultimately make Alexa’s speech sound more natural and enable the ability to vary its speaking style based on context. A ‘newscaster style’ speaking voice will launch on Alexa-enabled devices in a couple of weeks.
Alexa scientists’ work on Amazon’s AI model, Neural TTS (text-to-speech), has been detailed in a series of forthcoming papers (currently under submission) in addition to an accompanying blog post written by Trevor Wood, Applied Science Manager, and Tom Merritt, an Applied Scientist. In the blog, Wood comments:
With the increased flexibility provided by NTTS, we can easily vary the speaking style of synthesized speech. For example, by augmenting a large, existing data set of style-neutral recordings with only a few hours of newscaster-style recordings, we have created a news-domain voice. That would have been impossible with previous techniques based on concatenative synthesis.
Concatenative synthesis is what Alexa currently uses and has been around since the 2000s. Generally speaking, concatenative synthesis involves breaking up speech samples into distinct sounds and then putting them back together in order to form new words and sentences. However, it is a long process and requires substantial databases of recorded speech to be analyzed, broken down, analyzed again, and reconstructed.
The NTTS System Allows Alexa to Learn Quickly and Speak More Naturally
Through the use of neural generative networks and multiple-style sequence-to-sequence models, the Alexa Speech Team is able to separately model aspects of speech that are independent of speaking style and aspects of speech that are particular to a single speaking style. This makes the speech sound more natural.
The NTTS system is made up of two components. The first is a sequence-to-sequence model, the second is a neural vocoder. The two components allow a new style of speech to be learned with just a few hours of supplementary data in the desired style. Here are examples that provide a comparison of speech synthesized using concatenative synthesis, NTTS with standard neutral style, and NTTS with newscaster style.
Concatenative:
Standard Neutral NTTS:
NTTS Newscaster:
Sequence-to-Sequence Model
A sequence-to-sequence model (seq2seq) is about training models to convert sequences from one domain to sequences in another domain. For example, a seq2seq model would be used to convert sentences in English into the same sentences in French. Both English and French have their own grammar, or way of sequencing a sentence, that will convey the same message.
Alexa’s NTTS system includes a seq2seq model: a neural network that converts a sequence of phonemes (the most basic units of language) into a sequence of spectrograms. Spectrograms are visual representations of the spectrum of frequencies of sound or other signals as they vary with time. The NTTS system outputs mel-spectrograms, meaning that their frequency bands are chosen to emphasize acoustic features that the human brain uses when processing speech. They are crucial in determining the tone Alexa speaks with.
By design, the Alexa Speech Team will train on the large data sets that built the general-purpose concatenative synthesis systems. According to Wood and Merritt, the seq2seq approach yields high-quality, natural-sounding voices with a limited variety of expression. The resultant speech is style-neutral.
To create a styled resultant speech, the Alexa Speech Team is able to leverage their style-neutral seq2seq method. Written in the blog post,
We train the model not only with phoneme sequences and the corresponding sequences of mel-spectrograms but with a “style encoding” that identifies the speaking style employed in the training example. With this approach, we can train a high-quality multiple-style sequence-to-sequence model by combining the larger amount of neutral-style speech data with just a few hours of supplementary data in the desired style. This is possible even when using an extremely simple style encoding.
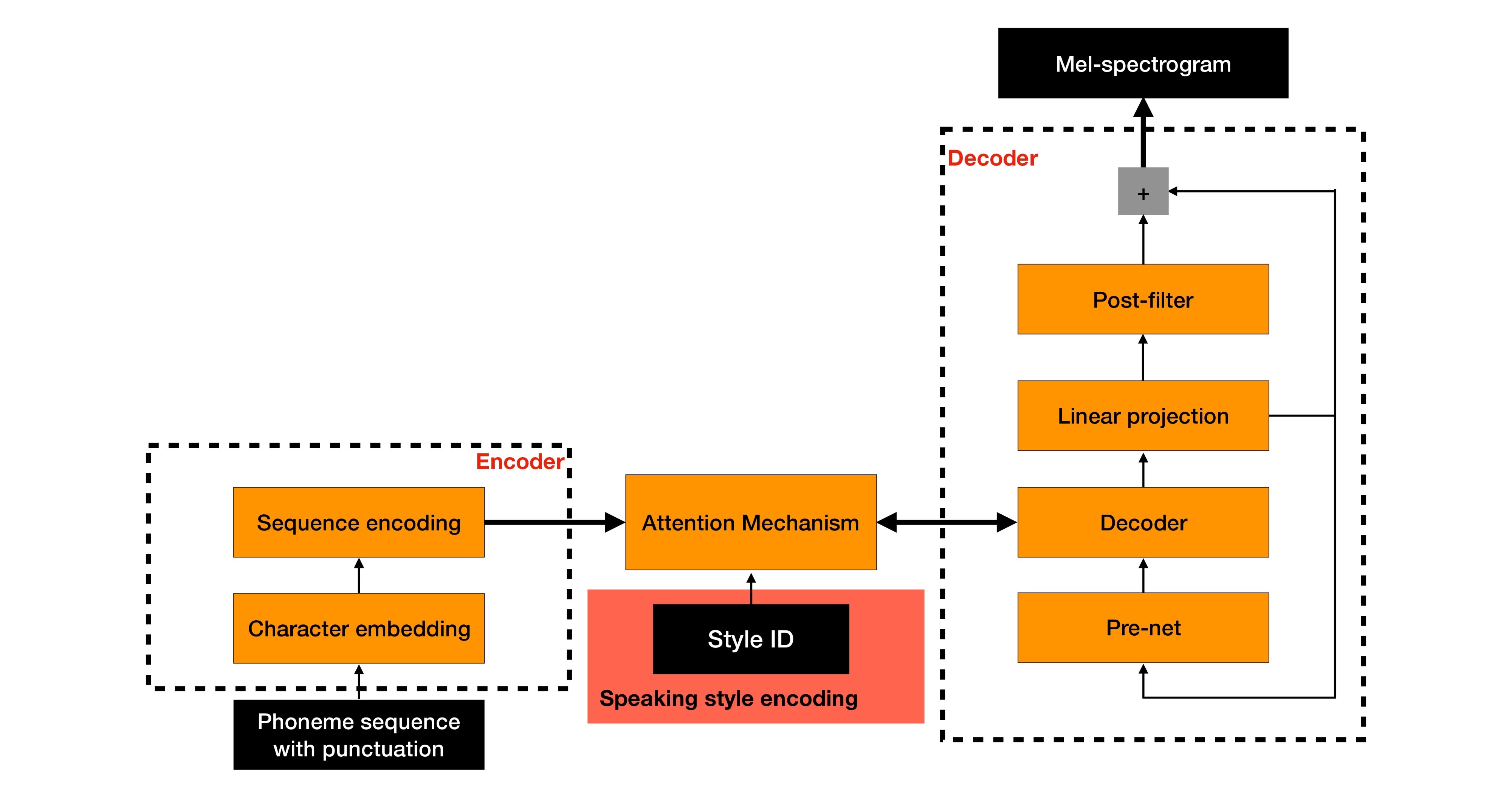
The sequence-to-sequence model topology used to generate mel-spectrograms. The added speaking-style encoding is highlighted in the red block.
Neural Vocoder
Typically, vocoders, a portmanteau of voice encoder, both encode and decode inputs in the process of analyzing and synthesizing voice. A neural vocoder is a neural network trained to convert mel-spectrograms into speech waveforms. Alexa’s neural vocoder takes mel-spectrograms from any speaker, regardless of whether he or she was seen during training time, and generates high-quality speech waveforms without the use of speaker encoding.
Perception of NTTS Style
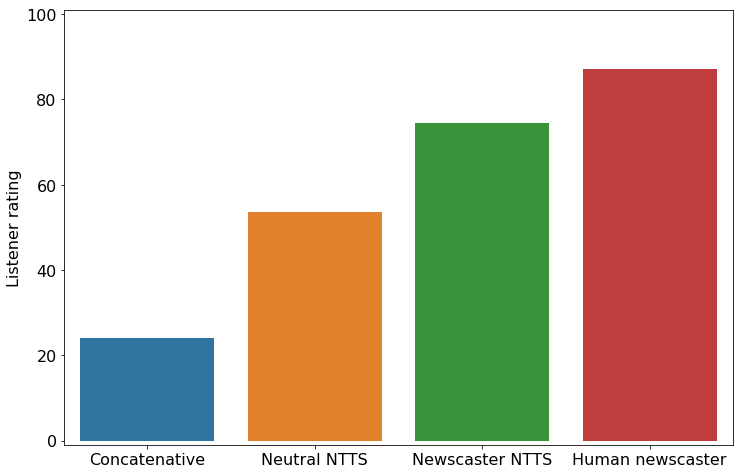
The Alexa Speech Team conducted a survey of listeners’ perception of the styled speech produced by the NTTS system, and they found that listeners rated neutral NTTS more highly than concatenative synthesis. Listeners also preferred the NTTS newscaster style more than either the concatenative synthesis or the NTTS neutral-style.
Here are the papers currently under submission produced by the Alexa Speech Team detailing the NTTS system.
- “Comprehensive Evaluation of Statistical Speech Waveform Synthesis”
- “Robust Universal Neural Vocoding”
- “Effect of Data Reduction on Sequence-to-Sequence Neural TTS”
What This Means for Alexa
This development will allow Alexa to personalize voices to consumers. We have already seen the introduciton of context-aware whisper mode. NTTS could yield an onslaught of new voice modes in 2019. Amazon told The Verge that a newscaster voice will arrive “in the coming weeks.” Whether or not these other voices will be context-aware, like whisper mode is, will be interesting to see. Some possible use-cases for Alexa changing vocal style could be for reading stories, playing games, or customer care in an informative skill.
It is easy to imagine Alexa using a dramatic voice for the telling of a scary story, or a character voice(s), similar to Alexios when playing a game. Even with informative apps, Alexa could become more cheerful when answering queries. Companies and independent developers could try to capitalize on this development by creating specific voice styles for their skills. The development of NTTS reinforces the idea that voice assistants need to become personalized to a user for them to view it as a necessity in their life.
Not only could this help with the tone of Alexa’s voice, but it could also help with the development of how Alexa interacts with accented speakers. Recordings of accented speakers could be used to train on, possibly helping with Alexa’s understanding of speakers.
Amazon Adds Alexa Skill Activation Metrics to Developer Dashboard






