
Alibaba Adds Visual Understanding to Open-Source Generative AI Large Language Models
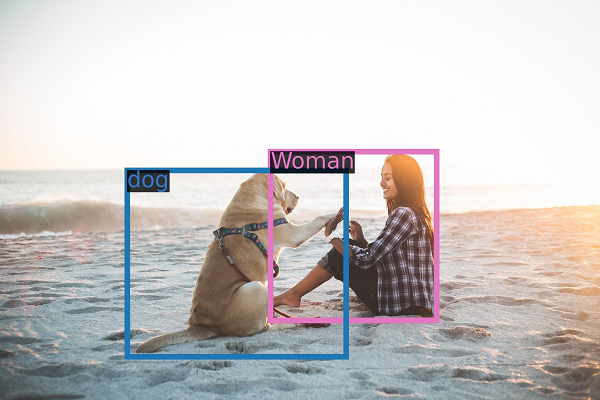 Chinese e-commerce giant Alibaba has added two new generative AI large language models designed to interpret images to its open-source stable. The new Qwen-VL and Qwen-VL-Chat models are built to handle complex visual conversations, automatically generating captions for images, answering questions about multiple photos, and even solving math problems based on visual depictions.
Chinese e-commerce giant Alibaba has added two new generative AI large language models designed to interpret images to its open-source stable. The new Qwen-VL and Qwen-VL-Chat models are built to handle complex visual conversations, automatically generating captions for images, answering questions about multiple photos, and even solving math problems based on visual depictions.
Visual Qwen
Qwen-VL and Qwen-VL-Chat represent a major advance in multimodal AI that can process different types of data like images and language. Qwen-VL builds off of Alibaba’s Qwen-7B language model by adding the ability to analyze visual inputs. The earlier model has seen more than 400,000 downloads since its debut earlier this month.
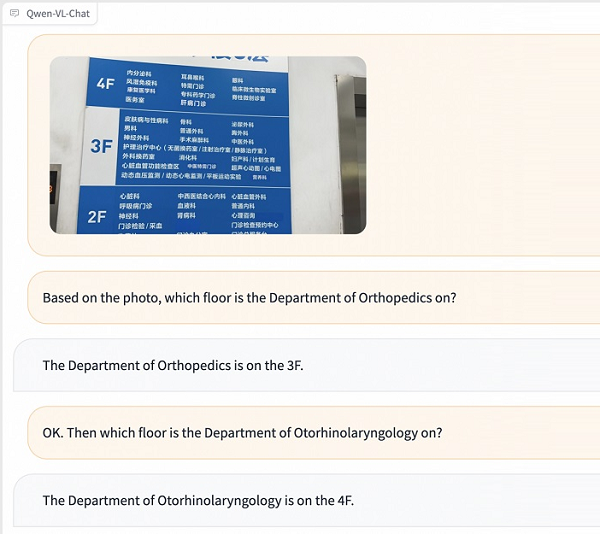 Qwen-VL is trained to recognize fine details in photos and can write captions describing an image, as well as explain what’s in it in response to queries. Qwen-VL-Chat, as seen on the right, uses Qwen-VL’s capabilities to enable dialogue involving images. This visual AI assistant can write stories based on photos, summarize a group of images, and answer multiple questions about them. The models represent progress in multimodal AI that understands connections between vision and language. They have the potential to enhance applications like assisting the visually impaired, automatically tagging photos, robot navigation using camera images, and more.
Qwen-VL is trained to recognize fine details in photos and can write captions describing an image, as well as explain what’s in it in response to queries. Qwen-VL-Chat, as seen on the right, uses Qwen-VL’s capabilities to enable dialogue involving images. This visual AI assistant can write stories based on photos, summarize a group of images, and answer multiple questions about them. The models represent progress in multimodal AI that understands connections between vision and language. They have the potential to enhance applications like assisting the visually impaired, automatically tagging photos, robot navigation using camera images, and more.
“Multimodality is one of the important technological evolution directions of general artificial intelligence. The industry generally believes that from a single-sensory language model that only supports text input to a multi-modal model that supports text, image, audio and other information input with “all five senses” it contains a huge leap in the intelligence of large models. Multimodality can improve the understanding of the world of the large model and fully expand the use scenarios of the large model,” Alibaba explained in a translated blog post. “Vision is the first sensory ability of human beings, and it is also the multimodal ability that researchers first want to endow large models with.”
By making these models open source and freely available, Alibaba Cloud aims to empower developers worldwide to create the next generation of AI products and services. The move also accelerates innovation in AI applications involving computer vision. By providing ready-made models that developers can build on rather than training from scratch, Alibaba lowers barriers to creating visual AI assistants, image classifiers, robotic navigation tools, and more.
The new models continue the competition among Chinese tech giants like Alibaba and Baidu to become China’s version of OpenAI in terms of dominance. As with the earlier models, however, Alibaba has to thread new government restrictions on generative AI. Beyond its in-house work, Alibaba also an agreement to support Meta’s new Llama 2 model and bring that open-source LLM to Chinese developers.
Follow @voicebotai Follow @erichschwartz
Alibaba Open-Sources Some Generative AI Large Language Models






