
Facebook Shares Two Giant Conversational AI Datasets
 Facebook has publicly shared two large conversational AI datasets publicly to encourage research and development to advance artificial intelligence and improve how well virtual assistants understand and interact with users. One dataset is supposed to help train an AI with only a tenth of the amount of raw data, while the other should help streamline developing multilingual voice assistants.
Facebook has publicly shared two large conversational AI datasets publicly to encourage research and development to advance artificial intelligence and improve how well virtual assistants understand and interact with users. One dataset is supposed to help train an AI with only a tenth of the amount of raw data, while the other should help streamline developing multilingual voice assistants.
Data Share
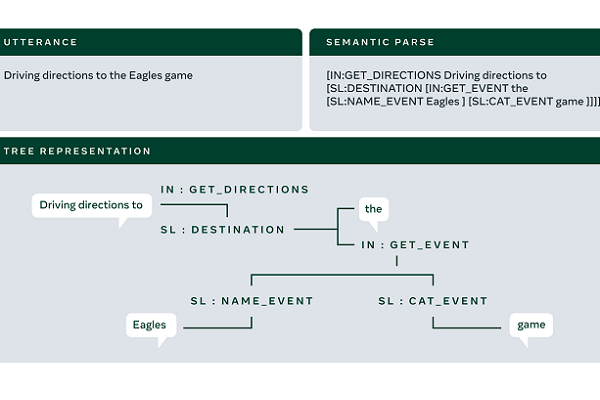
The datasets were crafted to better grapple with the restrictions of labeled training data. Conversational AI traditionally requires using huge amounts of information to train a natural language understanding engine before effectively understanding and interacting with users. The TOPv2 multidomain data set includes a seemingly impressive eight domains and more than 180,000 annotated samples. Facebook has improved its models to 10 times the efficiency in using data to learn. The compact data requirements extend to adding new domains as well. Each new intent and response can be added with just 25 recording samples.
The demand for huge datasets plagues the development of multilingual AI similarly, essentially duplicating all of the work from the initial language in terms of both translations and retraining the AI. Facebook’s efforts to reduce the resource demands and simplify the process led to the company creating and now sharing the MTOP dataset. MTOP covering six languages and around 100,000 create better software for that purpose
“Conversational AI and digital assistants are advancing rapidly, enabling much more complex and helpful uses, but these improvements are often limited to people who speak widely used languages such as English. Moreover, it is often very difficult to scale an existing model to support new use cases,” Facebook’s Ai researchers explained in a blog post. “By scaling NLU models to support more diverse use cases in more languages, especially ones that lack extensive collections of labeled training data, we can democratize conversational AI and bring this technology to many more people.”
AI Education
The design and release of the dataset are part of Facebook’s ongoing conversational AI research and sharing of the results and method. Back in February, Facebook shared the massive speech recognition database and training tool called Multilingual LibriSpeech (MLS) as an open-source dataset with more than 50,000 hours of audio in eight languages from public domain audiobooks with pre-trained language models and other data. Both such projects could be augmented or added to the M2M sigil. In October last year, Facebook shared a translation model that could shift between any two of 100 languages called M2M-100. Notably, it was built without using English. Meanwhile, the AI proved capable of understanding 51 languages, built on more than 16,000 hours of voice recordings.
“Open data sets and benchmarks have been key drivers of recent advances across AI. MLS provides a valuable resource for research in large-scale training of ASR systems,” the researchers behind the project explained in a blog post. “While there are data sets and benchmarks for non-English languages, they are often relatively small or scattered around different places and rarely available under an open, permissive license. We believe that by providing a large multilingual data set with a nonrestrictive license and establishing a common benchmark, MLS will promote open and collaborative research in multilingual ASR and improve speech recognition systems in more languages around the world.”
Follow @voicebotai Follow @erichschwartz
Facebook Makes Multilingual Speech Recognition Model Open Source
Facebook Shares 100-Language Translation Model, First Without English Reliance
Facebook Builds Speech Recognition Engine Combining 51 Languages in One Model






