

Wikipedia Will Start Charging Tech Giants and Their Voice Assistants for Data Access
 Voice assistants may soon need to pay Wikipedia to find answers to some of the questions users pose. The Wikimedia Foundation, the umbrella organization that encompasses Wikipedia and its sibling wiki-projects, is launching Wikimedia Enterprise to start packaging and selling Wikipedia’s content to Apple, Amazon, Facebook, and Google, including their respective voice assistants, as first reported by Wired.
Voice assistants may soon need to pay Wikipedia to find answers to some of the questions users pose. The Wikimedia Foundation, the umbrella organization that encompasses Wikipedia and its sibling wiki-projects, is launching Wikimedia Enterprise to start packaging and selling Wikipedia’s content to Apple, Amazon, Facebook, and Google, including their respective voice assistants, as first reported by Wired.
Knowledge Economy
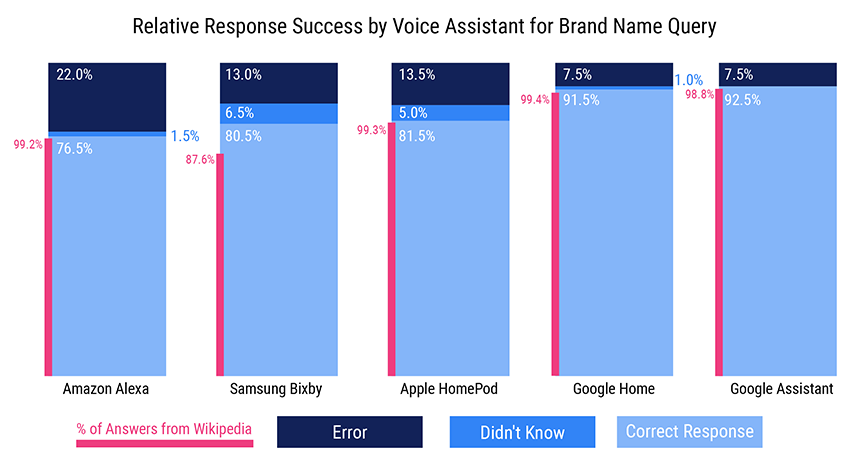
Answering questions is consistently among the most popular ways people use voice assistants. A Voicebot study of smart speaker use last year put asking questions at number two for use case frequency, just below listening to music. And Wikipedia is a crucial source of plenty of that information. That’s especially true when it comes to common questions about brands. Voicebot’s Voice Assistant SEO for Brands report in 2019 determined that Alexa, Google Assistant, and Siri relied on Wikipedia for 99% of correct answers to questions about a brand.
 Wikipedia supplies all of its information to the voice assistants with a combination of regular data drops and real-time updates to the information sought and cited by Siri, Alexa, Google Assistant, and other voice assistants. Each company has a group dedicated to sorting and organizing that information, reformatting it for use by their AI platforms. Voice assistants are only one of the platforms that use Wikipedia directly or indirectly. Wikimedia Enterprise’s API could be used to enhance navigation systems, search engines, mobile apps, and other programs that already turn to Wikipedia for information.
Wikipedia supplies all of its information to the voice assistants with a combination of regular data drops and real-time updates to the information sought and cited by Siri, Alexa, Google Assistant, and other voice assistants. Each company has a group dedicated to sorting and organizing that information, reformatting it for use by their AI platforms. Voice assistants are only one of the platforms that use Wikipedia directly or indirectly. Wikimedia Enterprise’s API could be used to enhance navigation systems, search engines, mobile apps, and other programs that already turn to Wikipedia for information.
Wikimedia Enterprise is already talking to the big four of tech about changing how they access Wikipedia’s database. The new model could be implemented as soon as this summer. The savings in time and resources usually spent basically duplicating Wikipedia’s work and the chance to have a more accessible customer service team, as opposed to the volunteer force in place at the moment, could be enormous. The existing model will still be available if they so choose, but Wikimedia Enterprise is angling to demonstrate how the companies will save much more than they spend by signing up for the pre-processed data flow.
“What many of the largest commercial technology organizations require in order to effectively utilize Wikimedia content goes beyond what we currently provide. Consequently, each of these large companies independently re-builds Wikimedia projects internally to address their very similar use-cases,” the Wikimedia Foundation wrote in an essay about the new plan. “The Wikimedia Enterprise API is a new service focused on use cases of high-volume commercial reusers of Wikimedia projects, that those entities can use at scale, and for which they will be charged.”
Information Overdrive
The voice assistants have other sources they can use to answer questions, but it’s hard to match Wikipedia’s breadth of subjects. For instance, Alexa uses Reuters to answer questions about the news, and Wolfram Alpha collaborated with Amazon to include its database of science and academic subjects in Alexa’s source list, while Google has its vast army of guides and reviewers updating information on Google Maps and other localized databases, but there’s nothing like the encyclopedia of information available on Wikipedia. Amazon has a Wikipedia-esque program called Alexa Answers, which crowdsources responses to questions from users the voice assistant couldn’t answer previously. People can submit their answers to any of the unanswered questions, and those answers may then be used as Alexa’s response to that question. But that is still in its infancy relatively, although Amazon did bring Alexa Answers to the United Kingdom last year to build a British-specific database as well.
While Wikimedia Enterprise’s focus, for now, is on the four colossi of the tech world, there are tentative plans to extend its sales to more companies that would like to upgrade their access to Wikipedia’s information. There’s no official decision on the pricing structure either, but it’s not as though four of the most successful tech companies ever couldn’t afford the cost of improving access to an incredibly useful database.
“This project represents a new kind of activity at the Foundation,” Wikimedia wrote. “The project is at a very early stage that should be considered a learning period. We will have successes, we will make mistakes, and we will need to adapt our strategies. The team is committed to listening, engaging, and where possible, integrating the feedback we get on our work.”
Follow @voicebotai Follow @erichschwartz






