
Cerence Reader Makes Earnings Call and Voice Tech History with Cloned Voices of CEO and CFO Presenting to Analysts

Cerence CEO Sanjay Dhawan (left) and CFO Mark Gallenberger
Cerence made history Monday by conducting the first earnings call by a public company to use cloned voices of the CEO and CFO to present financial performance data to financial analysts. Synthetic voices of Cerence CEO Sanjay Dhawan and CFO Mark Gallenberger were cloned using the Cerence Reader technology. The solution was used for text-to-speech conversion that read the official statements from Dhawan and Gallenberger about the 2020 fiscal year and fourth-quarter results (which beat analyst estimates). Richard Yerganian, vice president of investor relations at Cerence introduced the call by remarking,
“On this conference call, we will be demonstrating Cerence technology. The prepared remarks will be read using our voice cloning technology driven by our neural AI-based system called GEEnE. What you are about to hear are computer AI-generated voice clones of Sanjay and Mark.”
After the statements made in the cloned voices of Dhawan and Gallenberger, both executives joined the call and answered questions directly from analysts. Dhawan commented about the experience saying, “The engineer in me was very excited about using Mark and my clone. And, I think this was the world’s first where an earnings call was done by a clone while Mark and I were sipping a cup of coffee and waiting our turn for the Q&A. It was an interesting experience.”
Lifelike Precision
Earnings calls are a staple of the investor relations community and provide a venue for public companies to communicate financial information to interested analysts and journalists beyond the earnings press release. It also is an efficient way to answer financial analyst questions in a semi-public forum so the company doesn’t have to worry about the risk of selective disclosure. If you have listened to one of these before, most involve company officers, typically the CEO and CFO, reading from prepared statements before taking questions. These are tightly scripted affairs prior to the question and answer session because the companies want to be careful about the disclosure of information and abiding by regulatory requirements.
From a practical standpoint, there is little difference between hearing a statement read by a text-to-speech engine or read verbatim by a company officer. It was in an odd way more comfortable and seemed more efficient to hear the synthetic voice read out the information as opposed to listening to a human under the unnatural constraints of only reading from a prepared text. And, you didn’t have to guess whether the executive might have gone off-script for a moment. That was not an option for Cerence Reader.
But you also have to consider the audience. The analysts that follow public companies get to know the CEO and CFO and build a level of familiarity and trust around their voices. There was a heightened sense of seriousness and authority of the presented material because it sounded like Dhawan and Gallenberger even though it was computer-generated. Any synthetic voice could be used. It would be presenting approved materials released by the company’s investor relations group. However, there is a subtle impression that the cloned voice carries more weight because it has the likeness of a real person in authority combined with the precision of an AI-based text-to-speech system.
Letting the GEEnE Out
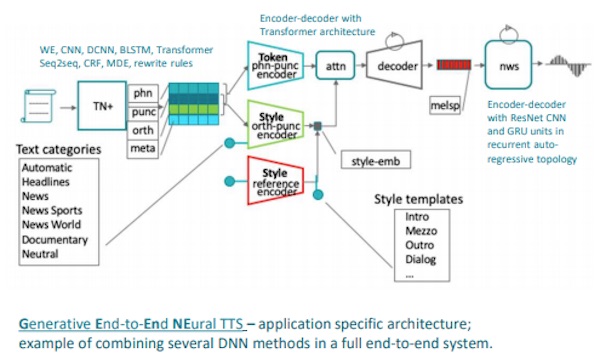
Cerence executed this experiment using its GEEnE technology–shorthand for generative-end-to-end speech synthesis. “GEEnE has the ability to learn to speak with different tones in different contexts, for example, as a newscaster reading the news,” a Cerence spokesperson shared with Voicebot via an email interview.
Voice cloning typically requires large amounts of recorded audio. It may be hours of data extracted from a wide range of “sentence types, styles, and intents.” GEEnE’s voice cloning technology was built from samples of large numbers of speakers to create a baseline synthetic speech model. You can think of this as a generic voice engine. It then can take much smaller recorded samples of other speakers and using AI transfer learning techniques manipulate the generic voice engine into a clone sounding like a specific person. In this case, “Sanjay and Mark…recorded their voice in their homes, on their laptops, by themselves, with a small amount of text,” according to the spokesperson.
The result was pretty impressive. While the synthetic voices lacked some of the dynamism of human expression (particularly in the long passages that were communicated), the similarity to Dhawan’s and Gallenberger’s voices in tone, style, and pronunciation was unmistakable. The energy level of the conversational exchanges was much higher as the call shifted to the Q&A portion and the real Sanjay and Mark spoke. However, that is true of almost all earnings calls anyway. The Q&A is always more dynamic than the prepared statements. It is the reason to listen to earnings calls because the answers were not prewritten by the investor relations team.
Dhawan commented in response to one analyst question saying, “Clearly, we need to train our AI model a little more on financial terms. I could see our clone was getting a little jittery when it came to ‘non-GAAP’ and some of those other words.” In reality, there were a couple of mistakes, but humans make pronunciation errors too.
Clones, Real People, and What it Means About Authenticity
I could this becoming standard practice for public companies. It clearly worked for Cerence this week and would have even if they didn’t have the alternative objective of showcasing their in-house technology. In the future, the CEO could approve the statement without having to prepare to read it and instead focus on prepping for the Q&A. It may be that all CEO acts have performative elements to them, but reading a prepared statement on an earnings call seems like the most performative and least useful rituals of the financial world.
The argument against this practice is that the CEO and CFO didn’t actually say the statements. A synthetic voice that sounded like them did. The statements were still official communications from the company and therefore are technically sanctioned by the corporate officers. However, there is a difference when you have the actual person making statements that you can refer back to and not simply the text written by a staffer that was rendered audibly by a synthetic voice. This is true even if a statement made by a CEO in their own voice was written by a staffer. It’s like two-factor authentication. The corporate officer approved of the statement that was written and then confirmed that approval by making the statement publicly.
AI-based systems now write news articles about earnings releases so it seems only fitting that AI-based systems can also be used to make the audible statements that accompany those announcements. Cerence gave everyone something to think about this week in terms of how we want or should use our voice technology in everyday activities. It also gave a really good demo of their technology.
If you would like to listen to the earnings call and check out the cloned voice technology, you can find an online presentation here.
Follow @bretkinsella Follow @voicebotai
Cerence Breaks Quarterly and Annual Revenue Records, Beats Pre-COVID Estimates
Cerence Adds Custom Wake Word Choices to Car Voice Assistants






