
Understanding is Crucial for Voice and AI: Testing and Training are Key To Monitoring and Improving It
Editor’s Note: This is a guest post written by Bespoken.io CEO John Kelvie
Benchmarking Voice Assistants
How well does your voice assistant understand and answer complex questions? It is often said, making complex things simple is the hardest task in programming, as well as the highest aim for any software creator. The same holds true for building for voice. And the key to ensuring an effortlessly simple experience for voice is the accuracy of understanding, achieved through testing and training.
To dig deeper into the process of testing and training for accuracy, Bespoken undertook a benchmark to test Amazon Echo Show 5, Apple iPad Mini, Google Nest Home Hub. This article explores what we learned through this research and the implications for the larger voice industry based on other products and services.
For the benchmark, we took a set of nearly 1,000 questions from the ComQA dataset and ran them against the three most popular voice assistants: Amazon Alexa, Apple Siri, and Google Assistant. The results were impressive – these questions were not easy, and the assistants handled them often with aplomb:
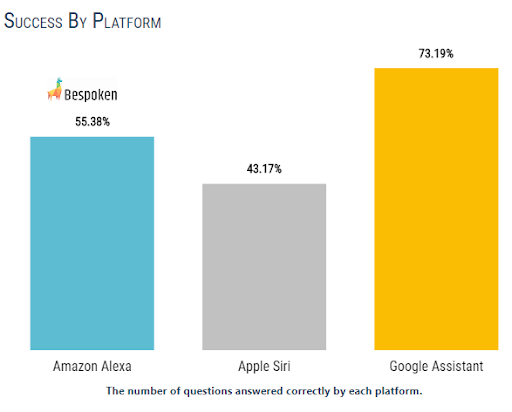
Google Assistant did especially well. Given Google’s preeminence in the search space, this perhaps does not come as a surprise. As important, and perhaps more surprising, Google also excels in UNDERSTANDING the user.
Understanding Is Key
To explain further, we probably expect Google to know:
“What is the least populated county in the state of Georgia?”
Not an easy question for a regular person, but eminently knowable, and the type of thing that Google and search engines excel at.
Then what about this:
“What year did the first men on the moon?”
Without the word “land” in there, it’s not clear what is being asked. But most of us could figure it out. And so could the assistants.
But then – how about this one:
“What largest us state is closer canada?”
You can read this a few times without making sense of it – the question may even seem rather unfair. If your head starts to hurt – there’s a quick remedy. Just pop it into Google Assistant, which replies:
There are 13 states that share a border with Canada. With 1,538 miles (2,475 km), Alaska shares the longest border.
Ahh, that feels right. Our benchmark shows that though all the assistants have room for improvement, they clearly are able to, in some ways, even exceed our own question parsing and answering ability as humans – quickly and correctly.
Accuracy Comes from Testing and Training
And this accuracy of understanding is critical to delivering great voice and AI experiences. Thankfully, the pathway to doing it is straightforward – testing and training. Testing means looking at all the ways users might interact with a voice application and seeing how well they work, just as we did with our benchmark. We run these commonly on behalf of our customers and typically see voice experiences have error rates of 20% or greater during initial baseline assessments.
But that is not a reason to despair! Training and tuning is the process to reduce these errors – it means revising and re-testing the model until it reaches an optimal level. This is an ongoing process that is essential to building for AI – we typically see reductions in errors of between 75-95% using simple techniques and even further improvements with more advanced but still straightforward techniques.
For example, in our work with the Mars Agency on behalf of a major cosmetics brand, testing and training reduced errors by more than 80% simply by adding in sounds-alike phrases to the Google Action speech model. These could be things such as when the user says “Ageless,” it is understood as “age list.” We don’t need to know all the complex algorithms involved in speech recognition to add “age list” as a synonym for ageless; once we know that one phrase is commonly mistaken for the other, it’s as easy as that to make dramatic improvements to accuracy. And further improvements, with more advanced approaches, are also readily achievable.
Testing Is A Continuous Process
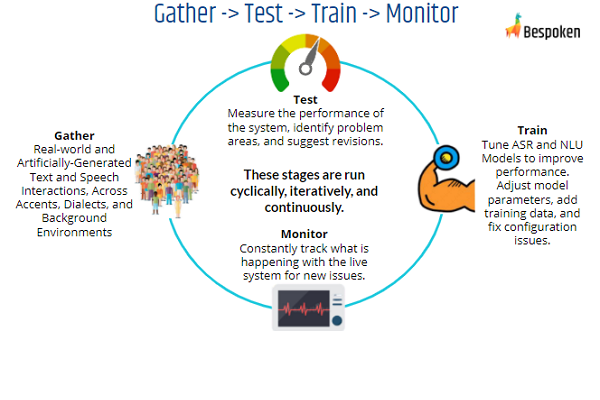
What’s more, this all works best when tied into a continuous integration/continuous testing process, facilitated by DevOps tools such as Github, Gitlab, and DataDog, which we used in our benchmark findings. When paired with in-depth testing and training regimens, these tools ensure voice experiences improve over time to consistently delight users. You can see the workflow we put together for our benchmark here – it’s all open-source. And the diagram below summarizes what we recommend as best practices for pulling these tools together for best-in-class accuracy and performance.
Roadmap For A First-Class Testing Regimen
 In summary, to apply this for your own projects, we recommend building off the five points listed below. Start with them to build a great testing, training, and monitoring regimen:
In summary, to apply this for your own projects, we recommend building off the five points listed below. Start with them to build a great testing, training, and monitoring regimen:
- Perform a baseline measurement – improvement is impossible without knowing your starting point.
- Identify areas of weakness – where users are frustrated & where the experience is degraded – and focus on fixing those.
- Leverage the available tools of the platforms such as synonyms and context management to make improvements
- Setup your DevOps – modern tools like Github and Gitlab make it easy to ensure testing is not a one-time event but a continuous part of your process
- KEEP TRAINING – building AI is inherently a continuous process, and the ongoing monitoring and tuning are as important, if not more important, than the initial development. The launch is just the beginning of the journey – enjoy it!






