
Google’s LIT Platform for Natural Language Model Testing is Now Open Source
 Researchers at Google have turned the Language Interpretability Tool (LIT) into an open-source platform for improving natural language processing models. LIT provides a way for developers to see and check how their AI model performs and why they may struggle in some cases. The wide use of Google’s automatic speech recognition suggests LIT could be useful for many organizations in tuning their assistants’ interactions.
Researchers at Google have turned the Language Interpretability Tool (LIT) into an open-source platform for improving natural language processing models. LIT provides a way for developers to see and check how their AI model performs and why they may struggle in some cases. The wide use of Google’s automatic speech recognition suggests LIT could be useful for many organizations in tuning their assistants’ interactions.
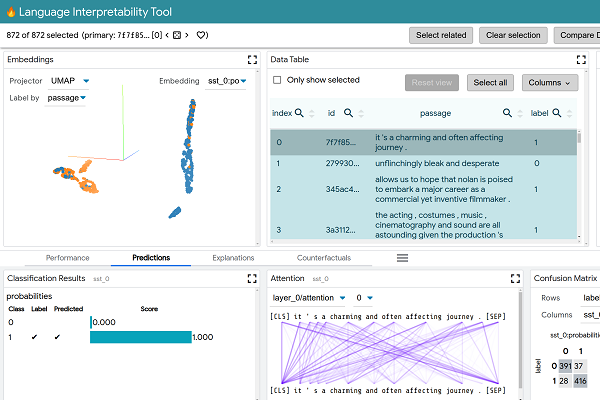
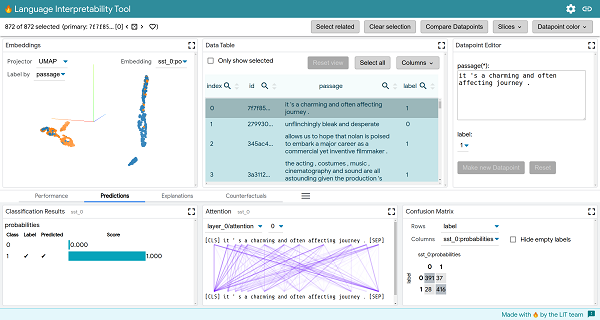
LIT View
Though NLP software has improved at a rapid rate, the models can still make mistakes, and the reasons for some of their behavior can be difficult to puzzle out even for their creators. Teasing out the threads is often complicated and challenging. LIT provides a way to see the analysis visualized, quickly testing many potential explanations for the model not performing as desired and comparing them to find out the AI’s logic. LIT can analyze how software models language, classifies input, and anticipates how a conversation might proceed, spotting biases and tendencies that might be hard to identify with raw data.
“We focus on core questions about model behavior,” the scientists explained in an academic paper about LIT. “Why did my model make this prediction? When does it perform poorly? What happens under a controlled change in the input? LIT integrates local explanations, aggregate analysis, and counterfactual generation into a streamlined, browser-based interface to enable rapid exploration and error analysis.”
ASR Assisting
Being interactive online does put limits on how well LIT handles more massive datasets compared to some offline options, and its flexibility prevents deep integration. The developers behind LIT put all of the documentation on GitHub, encouraging others to use and experiment with the software. The researchers aren’t done with LIT, either, and are planning more measurements and visualization tools, along with more customization.
LIT doesn’t solve all of the analytical questions, but it does at least provide a window on where to begin improving the algorithms. Independent and specialized voice assistant developers might use it to test where there are gaps in a voice assistant trained to be accessible to those with speech impediments or that it doesn’t make assumptions about gender based on occupation, as the researchers demonstrated in their article.
“Despite the recent explosion of work on model understanding and evaluation, there is no “silver bullet” for analysis,” the researchers wrote. “LIT provides first-class support for counterfactual generation: new datapoints can be added on the fly, and their effect on the model visualized immediately.”
Follow @voicebotai Follow @erichschwartz
Amazon and SK Telecom Are Working on a Korean Natural Language Processor
Voice Match is for the Birds: New Google Competition Seeks Avian Audio AI






