
Google is Using AI to Fill in Gaps in Duo Calls
 Google is using artificial intelligence to improve audio on its Duo video messaging app. The new WaveNetEQ algorithm to smooth out phone calls fill in brief gaps in the sound realistically enough to go unnoticed by the call’s participants.
Google is using artificial intelligence to improve audio on its Duo video messaging app. The new WaveNetEQ algorithm to smooth out phone calls fill in brief gaps in the sound realistically enough to go unnoticed by the call’s participants.
Packet Filler
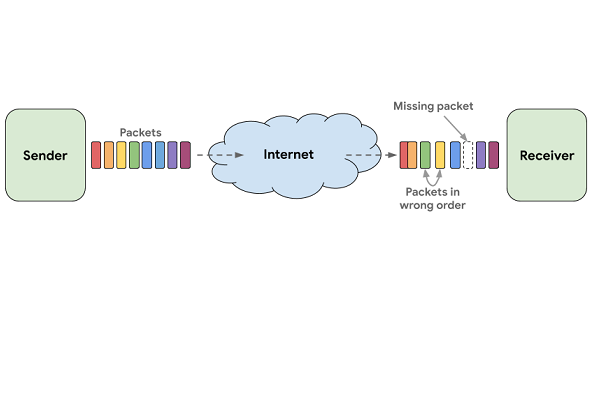
Digital phone calls, whether or not they have video, are made up of a stream of small sets of data. No wireless transmission system is perfect, which means some of those bits of information are lost along the way, leading to the often annoying crackles and spaces in the sound. Improving voice and video calls have taken on a new urgency during the current COVID-19 pandemic. With people staying home for the sake of public health, personal and work calls are now a central feature of many people’s days. Dropped calls or poor quality sound is not going to convince people to use Duo rather than Zoom or another platform. Google admits that only 1% of calls on Duo have no network delays or interruptions. A tenth of all Duo calls drop 8% of the audio, while fully 20% of Duo calls lose a smaller but still potentially vital 3% of their audio. Depending on where the blank spots are, the call may end up pointless.
WaveNetEQ rectifies the issue using what’s known as packet loss concealment.” Using a large database of recorded speech, the AI learns how humans talk and substitutes an artificial sound that it predicts will match what was being said using phonetics. The packets are tiny, which means the gaps usually are as well. The AI will only fill in 120 milliseconds of missing sound, including enough to overlap slightly with the speaker’s voice as it returns. That’s enough to make up for losing the signal for a moment, but the generated sound then fades to silence.
Wave Prediction
The new feature is built on the WaveRNN technology developed by Google’s DeepMind subsidiary. It’s related to the WaveNet technology used by Google to generate synthetic voices for Google Assistant and enterprise clients. Duo uses end-to-end encryption, so the algorithm operates from the receiver’s device. Running on the phone without needing to communicate with the cloud is part of what makes the model work fast enough to be invisible to people on the call. WaveNetEQ is trained in 48 languages, and the feature is on the Google Pixel 4 smartphone, with other Android devices to follow. Google has not said if the model will be part of the Duo app on different operating systems.
“As a [text-to-speech] model, WaveRNN is supplied with the information of what it is supposed to say and how to say it. The conditioning network directly receives this information as input in form of the phonemes that make up the words and additional prosody features (i.e., all non-text information like intonation or pitch),” Google’s researchers explained in a blog post. “In a way, the conditioning network can “see into the future” and then steer the autoregressive network towards the right waveforms to match it. In the case of a PLC system and real-time communication, this context is not provided. For a functional PLC system, one must both extract contextual information from the current speech (i.e., the past), and generate a plausible sound to continue it. Our solution, WaveNetEQ, does both at the same time.”
Follow @voicebotai Follow @erichschwartz
John Legend is Leaving Google Assistant, but Custom Voices are Just Getting Warmed Up
Amazon is Helping Brands Create Custom Alexa Voices Starting with KFC






