

Amazon Alexa Machine Learning Team Develops New Approach to Offline Voice Assistant Usage
Recent breakthroughs that have brought us modern-day voice assistants tend to have a common element, the cloud. Deep learning neural networks have proven to be important developments for the speed and robustness of natural language processing (NLP) solutions, but they require a lot of processing power. That typically means voice assistants in smart speakers, on smartphones and in other devices require high speed internet access to function. However, there are many use cases where internet connectivity may be unreliable or unavailable for a period of time. Automobiles are one such situation where offline voice assistant performance is critical.
Amazon has two recent research papers related to offline voice assistant use. One from the Alexa Machine Learning team is enticingly titled, Statistical Model Compression for Small-Footprint Natural Language Understanding. The paper succinctly outlines the situation:
“Voice-assistants with natural language understanding (NLU), such as Amazon Alexa, Apple Siri, Google Assistant, and Microsoft Cortana, are increasing in popularity. However with their popularity, there is a growing demand to support availability in many contexts and wide range of functionality. To support Alexa in contexts with no internet connection, Panasonic and Amazon announced a partnership to bring offline voice control services to car navigation commands, temperature control, and music playback. These services are “offline” because the local system running the voice-assistant may not have an internet access. Thus, instead of sending the user’s request for cloud-based processing, everything including NLU has to be performed locally on a hardware restricted device. However, cloud-based NLU models have large memory footprints which make them unsuitable for local system deployment without appropriate compression.”
Packing Alexa into a Smaller Memory Footprint
The research focused on implementing Alexa functionality on a device with limited processing power and memory that could be utilized within a mobile, unconnected environment. To do this, the approach was to create algorithms which could shrink large statistical NLU models into a smaller memory footprint. The solution was evaluated against three criteria: time, space and predictive performance. It involved combining two techniques called statistical model compression quantization and perfect hashing. Each individually yielded “moderate model size reduction,” but they were combined to deliver more significant compression rates.
Amazon’s solution included six domains in three different NLU models with feature counts that ranged from 500,000 to several million. Compression rate results were as high as 31.5 for the IC model.
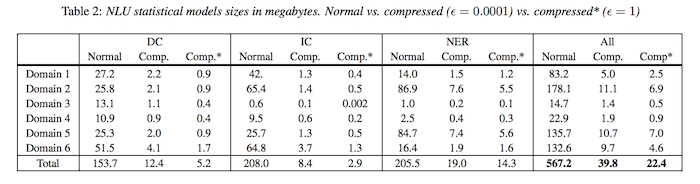
The new techniques dramatically reduced NLU model size, but the trade-off is typically performance. Study results show that error rates for the compressed NLUs rose only about 1-3%. Some implementation and domain combinations were as low as a 0.01% error rate increase while the largest increase was 8.94%.
Offline Use Cases
This type of research is critical to enabling voice assistant technology to support offline use cases. Performance breakthroughs that require large processing or memory footprints to execute ultimately will not succeed in automotive or other use cases where cloud access cannot be assured. There is a lot of focus on new language model development and improving the NLU performance when online access is available. An improvement by Siri for local point of interest identification is a recent example. However, voice assistant innovation isn’t always about getting bigger and better. Sometimes, it will be about getting smaller and not much worse. That will be a reasonable sacrifice to enable offline use cases.
Follow @bretkinsellaFollow @voicebotai
Amazon Auto to Bring Alexa Onboard and Offline Use Cases to Panasonic Infotainment Systems
Siri Gets Smarter at Recognizing Names of Local Businesses and Attractions
Google Assistant Integrated into Panasonic Auto Infotainment Systems Too






