

Google Launches New Text-to-Speech Cloud Service

Google has released a new text-to-speech cloud service for speech synthesis. It leverages DeepMind’s WaveNet technology running on Google’s cloud-based neural networks. This follows Google’s release, along with a team of researchers from the University of California at Berkeley, of findings in December that using WaveNet with Tactotron-2 neural networks delivered synthetic voices that sound more humanlike.
Google Cloud Text-to-Speech enables developers to synthesize natural-sounding speech with 30 voices, available in multiple languages and variants.
There are 32 voices offered in “12 languages and variants with more coming soon,” says the product page. It also supports SSML so developers can add pauses, pronunciation instructions and enable number and data formatting. And, you can modify the speaking rate, pitch and volume of each voice.
Pricing Similar to Amazon Polly, Unless You Use WaveNet
The new Google solution offers a free tier of up to one million or four million characters and then $4 or $16 rate per additional million characters depending on whether you use Standard or WaveNet voices. This means many developers will be able to use the new solution without speech synthesis costs. However, there may be Google cloud platform processing costs.
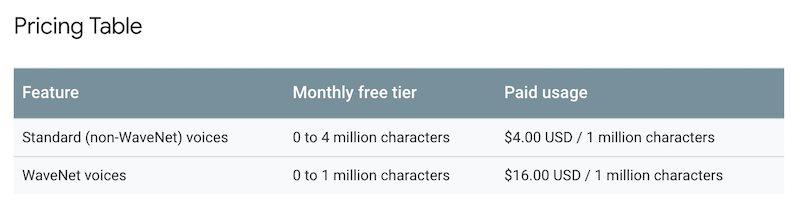
Pricing for standard voices is similar to what Amazon offers for its Polly speech synthesis service. That model offers one year free of up to five million characters per month, but thereafter charges $4 per one million characters. Amazon provides a handy conversion chart that indicates one million characters is about 23 hours and 8 minutes of speech. An average email message may have 3,100 characters and would cost about $0.02 and include about four minutes of speech whereas a typical news article has about 6,500 characters, would translate into about 9 minutes of speech and cost $0.03. To get a sense of what it would cost to reproduce a book in synthetic speech on Amazon Polly, “Adventures of Huckleberry Finn” by Mark Twain is offered as an example. It has about 600,000 characters in 224 pages. That is about 13 hours and 50 minutes of speech and would cost $2.40 on Polly.
Given that Polly and Google Standard voices are similarly priced, we can assume it would be about the same. However, many users will be interested in the higher humanlike fidelity of the WaveNet voices and you can assume the prices would be four times higher for the examples listed above. The Verge had a couple of samples of standard concatenative and WaveNet Google text-to-speech treatment of a short phrase.
Standard Speech Synthesis
WaveNet Speech Synthesis
The Verge article summarizes the different approaches nicely by saying, “Most voice synthesizers (including Apple’s Siri) use what’s called concatenative synthesis, in which a program stores individual syllables — sounds such as “ba,” “sht,” and “oo” — and pieces them together on the fly to form words and sentences. This method has gotten pretty good over the years, but it still sounds stilted…WaveNet, by comparison, uses machine learning to generate audio from scratch. It actually analyzes the waveforms from a huge database of human speech and re-creates them at a rate of 24,000 samples per second. The end result includes voices with subtleties like lip smacks and accents.”
Why Does This Matter?
The move by Google matters to the voice industry because it provides more options for a richer user experiences (UX) through voice apps on Google Assistant, Amazon Alexa and other services. Most voice apps today utilize standard Google Assistant voices or the Alexa voice for text-to-speech conversion. However, that doesn’t create much differentiation for voice apps when they all use the same voice. The richest UX with differentiation involves using a voice actor to read the content. However, that is impractical for many voice apps that have voluminous or regularly changing content and it can also become expensive. Synthetic speech addresses that problem by providing differentiation, but can be easily changed and updated all at a low cost. The more humanlike synthetic speech sounds, the better the trade-off versus voice actors.
I was asked recently if I knew about options other than Amazon Polly that developers should consider for adding synthetic text-to-speech to their voice apps. The list of alternatives was short, but Google’s new text-to-speech solution provides a much more robust set of voice options that are easily accessible to developers.






