
Baidu Reports on Neural Voice Cloning Advances
How would you like your Amazon Echo or Google Home to sound like Theo James, Christopher Walken or Beyoncé? What about projecting your mother’s voice? You may recall reports about the University of Montreal students that developed Lyrebird in 2017. It created an interesting mashup of Barak Obama, Donald Trump and Hillary Clinton having a fake conversation about Lyrebird technology. The conversation won’t fool many listeners, but the impressive thing was that it captured unique aspects of each person’s voice discussing topics that weren’t remotely close to speech used in the recorded audio for the voice model.
Since then, Lyrebird has launched a product and has a fun demo page showing how it can read Tweets to you in the synthesized voice roughly similar to the current and previous U.S. presidents using the technology. You can also create your own digital voice. The company claims to only require one minute of recorded audio to generate the voice clone, but the similarity increases with more spoken audio to draw from. The company’s beta tool suggests capturing several minutes of audio capture to create a more compelling facsimile.
Baidu Neural Voice Cloning Hopes to Progress Even Further
Researchers at Baidu have constructed a study that takes this further and opens up new application possibilities. The Baidu team sought to determine at what point you encounter diminishing returns from capturing additional voice data and what you can accomplish with a smaller data set. It also wanted to learn if you could alter an accent from an existing speaker. The Register offered a good summary:
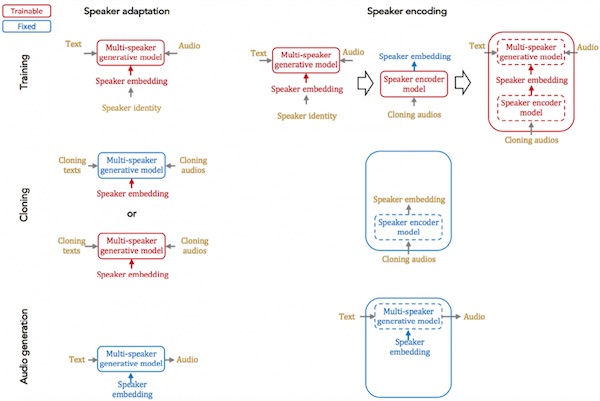
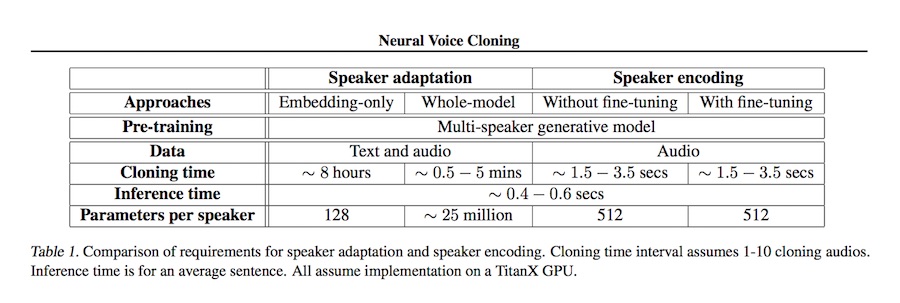
“The researchers introduce two different approaches to building a neural cloning system: speaker adaptation and speaker encoding. Speaker adaptation involves training a model on various speakers with different voices. The team used the LibriSpeech dataset, containing 2,484 speakers, to do this. The system learns to extract features from a person’s speech in order to mimic the subtle details of their pronunciation and rhythm.
“Speaker encoding involves training a model to learn the particular voice embeddings from a speaker, and reproduces audio samples with a separate system that has been trained on many speakers…Sercan Arik, co-author of the paper and a research scientist at Baidu Research, explained to The Register that the speaker encoding method is much easier to implement in real life for speakers such as digital assistants compared to the speaker adaptation technique.”
Arik commented in the interview:
A speaker adaptation approach requires users to read a specific utterance from a given text, whereas speaker encoding works with random utterances. This means speaker adaptation may not be as easily deployed on user devices, as it has more challenges to scale up to many users. Instead, speaker encoding is much easier for deployment purposes – it can even be deployed on a smartphone – as it is fast and has low memory requirements.
It is very fast according to the study results. The cloned voice using speaker encoding can be generated in just a few seconds compared to a few minutes to several hours for speaker adaptation.
 Voice Synthesis is Improving and Baidu is a Leading Innovator
Voice Synthesis is Improving and Baidu is a Leading Innovator
Both The Register article about the Baidu Research findings and The Verge article about Lyrebird touched on the concern about identity theft. To the extent the voice biometrics become more widely used–Google Assistant and Amazon Alexa are both offering a version of this capability–and the technology improves significantly, this is a legitimate concern. Anyone could use these tools to synthesize a person’s voice based on publicly available audio content or potentially surreptitiously recording a conversation. This is a risk.
However, the other way to interpret the findings is to recognize how quickly speech technology is advancing and the leadership position Baidu is establishing. Lyrebird talks about recreating the voice of people that have lost the ability to speak so they can express their authentic selves through the technology. Baidu is more likely considering how the technology can be used to personalize a consumer voice assistant. The study findings and technology demonstrations show us that not only will synthesized voices become more humanlike (see Google study on this topic), they will be customizable to sound like people we know. Human voices that we are familiar with evoke emotional connections. Our voice assistants seem destined to borrow from those pre-existing emotional connections to generate more humanlike experiences and relationships for users.
You can hear some examples from the Baidu study here. They don’t sound very humanlike in this form but consider this: some of these were generated with only a few audio samples of random spoken conversation. This study is in many ways about how you can do a lot with very little source data.
Follow @bretkinsella
Microsoft Hits New Conversational Speech Recognition Milestone






